Sequence Data Types#
Sequences are data types that organize groups of objects
Text sequences –
strBinary sequences –
bytes,bytearrayGeneral sequence types – can contain dissimilar Python objects
list,tuple,range
Sequences are either mutable or immutable
Immutable –
str,bytes,tuple,rangeCannot be modified without creating a new object
Mutable –
list,bytearrayCan be modified in-place after definition
Sequences support operations such as indexing, slicing, concatenation, etc.
String Sequences#
A string is a sequence of characters
Note: Python does not have a char data type
lenfunction gives the length of the text sequence
s1 = 'Hello\nWorld!'
len(s1)
12
s2 = '''a
b
c'''
len(s2)
5
s3 = '''a\
b\
c'''
len(s3)
3
Indexing#
Each element of a sequence is associated with an integer, referred to as an index
Index denotes the location of the element within the sequence
The indices go sequentially from 0 to n-1
n = number of elements in the sequence, i.e., its length
0 is the index of the 1st element and n-1 is the index of the last element
Each element also possesses a negative index \(j\) given by \(j = i - n\)
\(i\) is the positive index (\(0 \le i \lt n\))
Consider the string, “Hello World!”
String |
H |
e |
l |
l |
o |
W |
o |
r |
l |
d |
! |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|
Index |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
Neg. Index |
-12 |
-11 |
-10 |
-9 |
-8 |
-7 |
-6 |
-5 |
-4 |
-3 |
-2 |
-1 |
Negative indices count backwards from last element
Indexing is performed using the
[]operator, e.g.,seq[expr]seqis the sequence objectexpris an expression which must evaluate to anintobject with a value between -n and n-1Indices beyond these limits results in an exception
s = "Hello World!"
s[0]
'H'
s[-12]
'H'
s[len(s)-1]
'!'
Slicing#
Slicing refers to using the
[ ]operator to access a subset of the sequenceSlicing format
\([i:j:\Delta]\) – extracts elements beginning from index \(i\) to \(j-1\) in increments of \(\Delta\)
\(i\), \(j\), and \(\Delta\) are integers (can be negative)
If \(j\) is not specified, it is assumed to be the length of the sequence
If \(i\) is not specified, it is assumed to be 0
If \(\Delta\) is not specified, it is assumed to be 1
s = 'Hello World!'
s[0:10:2]
'HloWr'
s[2::2]
'loWrd'
s[1:5]
'ello'
s[-4:]
'rld!'
s[::-1]
'!dlroW olleH'
Methods#
The
strclass provides many methods to work with string objectsThe
dirfunction can be used to list these methods
print(dir(str))
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'removeprefix', 'removesuffix', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
Some useful functions:
islowerandisupperFunction that returns
Trueif:the string is not empty and all the alphabet characters are in lower/upper case
isalpha-Trueif all characters are alphabets and string is not emptyisnumeric-Trueif the string is exclusively made of digts 0-9 and string is not emptyisalnum-Trueif the characters are all either alphabets or numbers
lower- converts upper-case characters to lower caseupper- converts lower-case characters to upper caseOther functions that alter the case of the alphabets:
title,capitalize,casefold, andswapcaseUse the
helpfunction to know more (e.g.,help(str.capitalize))
count- outputs the number of occurrences of a character or a sub-stringfind- outputs the index of the first occurence of a character or a sub-stringOutput is -1 if not found
quote = "I think, therefore I am."
quote.count('I')
2
quote.count('z')
0
quote.find('think')
2
quote.find('zoo')
-1
replace(s1, s2)- replaces sub-strings1with sub-strings2split(d)- splits the string usingdas the delimiter
s = "He uses Python."
s.replace('He', "She")
'She uses Python.'
names = "Isaac Newton, Leo Euler, Joe Lagrange, Dan Bernoulli, Will Hamilton"
names.split(', ')
['Isaac Newton', 'Leo Euler', 'Joe Lagrange', 'Dan Bernoulli', 'Will Hamilton']
Formatted Strings#
Strings can be formatted for their appearance through either:
formatmethod, orf-strings (short for formatted strings)
String formatting also allows string literals to be combined with expressions
x = 10
y = 20
# An f-string
s = f'{x} times {y} = {x*y}'
s
'10 times 20 = 200'
f-strings are defined just like normal strings but are preceded by either f or F
Any expression enclosed within curly braces, like so
{expr}, is evaluated and replaced to form a new string
s = 'WSU'
f'{s[0]} - {s[1]} - {s[2]}'
'W - S - U'
c = 4 + 7j
f'Imaginary part of {c} is {c.imag}'
'Imaginary part of (4+7j) is 7.0'
The braces used in f-strings are referred to as replacement fields
Along with an expression, format specifiers can be included in the replacement fields
Template for a replacement field:
Conversion field can be either:
sfor string conversion;str(expr)replaces the replacement fieldrfor canonical string representation of the object;repr(expr)is used to replaceafor ASCII representation; output ofascii(expr)is placed
For the numeric types, the conversion field has no effect
Format specifier appears after
:in the replacement field
It is not part of the f-string, but helps format it
Format specification is itself a mini-language
Refer to the documentation for a complete description: Format specification mini-language
Important features of a format specifier
Fill, alignment, and width
Sign and precision
Type
Format specification: Fill, alignment, and width
Fill is by default the space character and can be modified to any other character except
{or}Optional but when specified, must specify the alignment field too
Alignment is optional and is specified by one of the following characters
<for left alignment>for right alignment (default behavior if not explicity specified)^for center alignment
Width is specified by an integer; determines the width (i.e., number of characters) of the f-string
x = 20
# f-string with no format specifier
f'{x}'
'20'
# With format specifier
f'{x:*^10}'
'****20****'
f = '_'
a = '^'
w = 10
# Format specifier for alignment
f'{x:{f}{a}{w}}'
'____20____'
f'{x:8}'
' 20'
Format specification: Sign
Must be used only for formatting expressions that evaluate to numbers
Sign field is placed before the width field and used to indicate the sign of positive numbers
Negative numbers are unaffected by the sign field
Use
+to put the + sign before the numberUse
-to add the sign only for negative numbers (default behavior)Use
x = 3.141592653589793
f'{x:+4}'
'+3.141592653589793'
Format specification: Precision
Determines the number of significant digits that appear for floating point numbers
Applicable to
floatdata type only; use with other data types results in an errorPrecision is specified by .p where p is a positive integer
f'{x:+4.4}'
'+3.142'
Format specification: Type
Valid only for numeric data types
Specified by a single character
Integer:
bfor binary representation of the integer; same as the output ofbin(expr)cfor character representation; output ofchr(expr)dfor decimal (default)ofor octal (base-8) representation; same as output ofoct(expr)xfor hexadecimal (base-16) representation; same as output ofhex(expr)
x = 2023
f'{x:c}'
'ߧ'
f'{x:x}'
'7e7'
hex(x)
'0x7e7'
int('0x7e7', 16)
2023
Format specification: Type
Valid only for numeric data types
Specified by a single character
Float or complex numbers:
ffor fixed number decimal pointsefor scientific notation (default)gfor general formatting (either fixed or scientific format is chosen depending on the magnitude)%for expressing numbers as percentages (not applicable tocomplex)
x = 3.141592653589793/100
f'{x:.4f}'
'0.0314'
f'{x:.4e}'
'3.1416e-02'
f'{x*10**0:.4g}'
'0.03142'
f'{x:.4%}'
'3.1416%'
Lists#
Lists allow organization of data (like to-do lists or grocery lists)
Enclosing square brackets
[ ]indicate lists in PythonThe elements of a list are enclosed within
[ ]and separated by a commaThe
lenfunction gives the number of elementsCan be homogenous (all elements are of the same datatype) or heterogenous (different datatypes)
Lists can contain other lists as elements
l1 = [1, 'abc', 3.2 + 4.5j]
l2 = [1, 2, l1]
print(l1)
print(l2)
[1, 'abc', (3.2+4.5j)]
[1, 2, [1, 'abc', (3.2+4.5j)]]
# An empty list
l3 = []
len(l3)
0
Indexing and slicing
Work the same way they do with
strsequences
x = [1, 2.2, 'string', 3+4j, 20] # A heterogenous list
y = [2, 4, 6, 8] # A homogeneous list
l = [2.4, 'abc', x, y]
l
[2.4, 'abc', [1, 2.2, 'string', (3+4j), 20], [2, 4, 6, 8]]
l[0]
2.4
l[-2]
[1, 2.2, 'string', (3+4j), 20]
Accessing element within an element
l[-2][2]
'string'
l[2][2][2]
'r'
Indexing and slicing
Work the same way they do with
strsequences
l
[2.4, 'abc', [1, 2.2, 'string', (3+4j), 20], [2, 4, 6, 8]]
l[0:2]
[2.4, 'abc']
l[2][::-1]
[20, (3+4j), 'string', 2.2, 1]
List Modification#
List is a mutable sequence type, i.e., it is modifiable
Different ways of modifying a list
Assignment operator (
=)append,extend, andinsertmethods to insert elementsclear,pop, andremovemethods to remove elements
l = [1, 2, 4, 10, 20]
# Modifying the 3rd element using indexing and assignment operator
l[2] = 8
print(l)
[1, 2, 8, 10, 20]
Variables are stored in memeroy with a unique ID which can be accessed with the
idfunction.Modifying a list does not alter its id
carMakers = ['Honda', 'Toyota', 'Ford', 'GM',\
'Volkswagen', 'BMW', 'Renault']
id(carMakers)
139682951992832
carMakers[3] = 'Kia'
print(carMakers)
['Honda', 'Toyota', 'Ford', 'Kia', 'Volkswagen', 'BMW', 'Renault']
id(carMakers)
139682951992832
A contiguous sub-list can be replaced by another list of any size
Only positive indices should be used for a sub-list to be treated contiguous
print(carMakers)
carMakers[3:5] = ['Rivian', 'Mercedes', 'Volvo']
print(carMakers)
['Honda', 'Toyota', 'Ford', 'Kia', 'Volkswagen', 'BMW', 'Renault']
['Honda', 'Toyota', 'Ford', 'Rivian', 'Mercedes', 'Volvo', 'BMW', 'Renault']
A non-contiguous sub-list cannot be replaced by a list of different size
Any attempt to do so will result in an exception
# Attempting to replace ['Honda', 'Ford'] with ['Hyundai', 'Nissan', 'Citroen']
carMakers[0:3:2] = ['Hyundai', 'Nissan', 'Citroen']
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[51], line 2
1 # Attempting to replace ['Honda', 'Ford'] with ['Hyundai', 'Nissan', 'Citroen']
----> 2 carMakers[0:3:2] = ['Hyundai', 'Nissan', 'Citroen']
ValueError: attempt to assign sequence of size 3 to extended slice of size 2
carMakers[0:3:2] = ['Hyundai', 'Nissan']
carMakers
['Hyundai',
'Toyota',
'Nissan',
'Rivian',
'Mercedes',
'Volvo',
'BMW',
'Renault']
Augmented assignment (
+=or*=) can be used to modify a list
l = [1, 2, 3]
l += [2, 3, 4]
print(l)
[1, 2, 3, 2, 3, 4]
l *= 2
print(l)
[1, 2, 3, 2, 3, 4, 1, 2, 3, 2, 3, 4]
x = [1, 2, 3]
y = [2, 4, 6]
z = x + y
z
[1, 2, 3, 2, 4, 6]
print(id(x), id(y), id(z), sep='\n')
22493298399488
22492932552512
22492939928704
w = z*2
print(w)
print(id(w))
[1, 2, 3, 2, 4, 6, 1, 2, 3, 2, 4, 6]
22492932707008
Methods#
Adding to a List#
appendmethod: Allows addition of an object to the end of the listextendmethod: Allows extension of the list with a given listinsertmethod: Allows insertion of an object before a specified indexIt takes two inputs – the first is the index at which to insert the second input
x = [0, 2, 4, 6, 8]
x.append(10)
x
[0, 2, 4, 6, 8, 10]
x.extend([12,16])
x
[0, 2, 4, 6, 8, 10, 12, 16]
x.insert(-1, 14)
x
[0, 2, 4, 6, 8, 10, 12, 14, 16]
x.insert(0, -2)
x
[-2, 0, 2, 4, 6, 8, 10, 12, 14, 16]
Removing from a List#
popmethod: Pops out an element from the listThe output is the popped element
The default behavior is to pop the last element
Element from a specified index can be popped
x = [-2, 0, 2, 4, 6, 8, 10, 12]
x.pop()
12
x.pop(0)
-2
x
[0, 2, 4, 6, 8, 10]
removemethod: Removes first occurrence of a given elementdelstatement: Delete individual elements or sub-lists through indexing and slicing, respectivelyclearmethod: Remove all elements and returns an empty list
x = [0, 1, 2]*2
x
[0, 1, 2, 0, 1, 2]
x.remove(0)
x
[1, 2, 0, 1, 2]
x.remove(2)
x
[1, 0, 1, 2]
del x[0]
x
[0, 1, 2]
del x[0::2]
x
[1]
x = [0, 1, 2]*3
x.clear()
x
[]
Identity Test Operator#
Keywords
isandis notare used to test if two objects are identical
x = "Hello!"
y = x
x == y
True
Logical operator
==compares the values stored in the object
x is y
True
x is not y
False
The identity test operators
isandis notcompare theidof the objectsIf the objects have the same
id, they will have the same values by definition
The
=operator typically creates a reference to the object
x = [0, 2, 4, 6, 8]
y = x
print(id(x))
print(id(y))
x is y
22492932552960
22492932552960
True
Modifying
ymodifiesxtoo
y.append(10)
print(y)
print(x)
[0, 2, 4, 6, 8, 10]
[0, 2, 4, 6, 8, 10]
Note: References lead to efficient memory usage and are commonplace in C++ programming
Other Methods#
copy– returns a copy of list (i.e., not a reference)
x = [0, 2, 4, 6, 8]
y = x.copy()
y == x
True
y is x
False
y.append(10)
print(y)
print(x)
[0, 2, 4, 6, 8, 10]
[0, 2, 4, 6, 8]
count– returns the number of occurrences of an element in the listindex– return the index of the first occurrence of the given element, like thefindmethod ofstrclass
x = [1, [2, 2], [3, 3, 3]]
x.count(3)
0
The
countmethod does not look inside the elements
sort– sorts the elementsWorks only if all the elements can be compared using the comparison operators
Typically, does not work with heterogenous lists
reverse– reverses a list in-placeReversing using slicing will create a copy
x = [0,5, 2, 1, 0.5, 15, -6]
x.sort()
x
[-6, 0, 0.5, 1, 2, 5, 15]
Membership Test Operator#
The keywords
inandnot inare the membership test operatorsReturn a Boolean value (True or False) after evaluating whether a given object is a member of a sequence type object
x = 'Hello World!'
'o W' not in x
False
'' in x
True
Empty string is considered a member of all string objects
a = [2, 4, 6, 8, 10]
2 in a
True
12 not in a
True
[2, 6] in a
False
While 2 and 6 are in
a, the sub-list[2, 6]is not ina
x = [1, [2, 2], [3, 3, 3]]
3 in x
False
Membership operator does not look inside each element
Tuples#
Tuples are like lists except they are immutable
Denoted by parentheses
( )and enclosed elements separated by commas
Methods –
countandindexSame behavior as with lists
Indexing and slicing work just the same as with other sequence types
Addition and multiplication are supported (a common feature of all sequence types)
l = [0, 2, 4, 6] # list
t = (0, 2, 4, 6) # tuple
t*2
(0, 2, 4, 6, 0, 2, 4, 6)
t1 = 0, 2, 4, 6 # The parentheses can be dropped
t2 = (1, 2.2, 'abc', 4+7j, True) # Heterogenous tuple
Note:
Square brackets
[]are used to denote alistas well as for indexing/slicingParentheses
()are used to denote atupleas well as for function calls
Lists vs. Tuples#
Tuples are immutable, lists are mutable
Tuples are more memory efficient
Tuples require less computational time to index, etc.
Use tuples when you do not need to modify the data in the sequence
Coversion between lists and tuples
Convert to list with
listfunctionConverft to tuple with
tuplefunction
a = (1,2,3,4,5)
b = list(a)
c = tuple(b)
print(a)
print(b)
print(c)
(1, 2, 3, 4, 5)
[1, 2, 3, 4, 5]
(1, 2, 3, 4, 5)
list('abc') # Converts a string to a list of individual characters
['a', 'b', 'c']
tuple('abc') # Converts a string to a tuple of individual characters
('a', 'b', 'c')
Ranges#
Range is another immutable sequence type
Takes three inputs and produces a sequence of integers
range(start, stop, increment)The start argument (or input) is optional; default value is 0
The increment argument is also optional and defaults to 1; can be negative
range(i, j, 1)producesi, i+1, i+2,⋯, j−1\(j \le i\) produces an empty range
x = range(11)
x
range(0, 11)
Use
listortuplefunction to convert therangeobject to a list or tuple
list(x)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
tuple(x)
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
Range objects only stores start, stop and increment values and have smaller memory footprint than lists and tuples
The sequence of numbers are generated on-the-fly
y = range(1001)
z = list(y)
# Size of the range and list object
import sys
print(sys.getsizeof(y), sys.getsizeof(z), sep='\n')
48
8072
Ranges support membership test operators, indexing, and slicing
Methods
countandindexwork the same way as they do withlistandtupleobjects
x = range(0, 20, 4)
1 in x
False
20 not in x
True
x[2]
8
x[::-1]
range(16, -4, -4)
Dictionaries#
A dictionary is a map of hashable objects (keys) to arbitrary objects (values)
An object is hashable if its value does not change
E.g., immutable objects of type
int,str,float,complexA tuple, although immutable, is hashable only if the elements are immutable too
Lists and dictionaries are mutable and hence not hashable
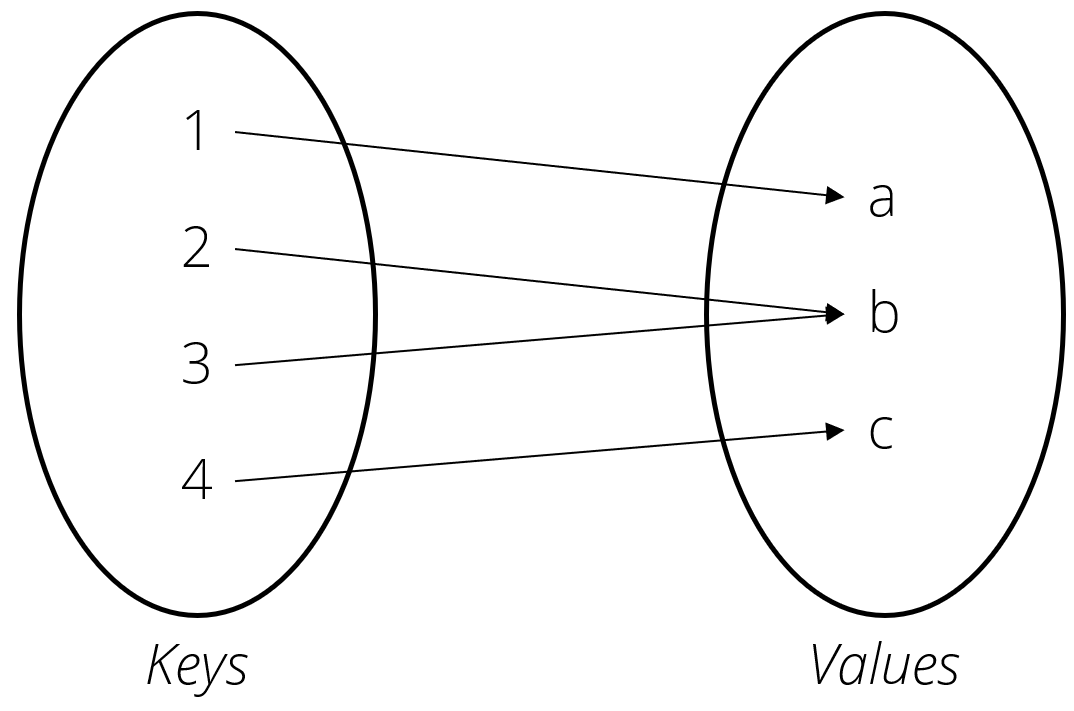
Dictionaries are defined as comma separated key : value pairs within braces
d = {key1 : value1,..., keyN : valueN}
The order of the key : value pairs is not important
Strings are commonly used for keys
Mutable – new key-value pairs can be added and values of existing keys modified
state1 = {1 : 'Washington', 2 : 'Olympia', 3 : 'Seattle'}
state1 = {"name" : "Washington", "capital" : "Olympia", "largest city" : "Seattle"}
state1['name']
'Washington'
state1['capital'] = 'Pullman'
state1
{'name': 'Washington', 'capital': 'Pullman', 'largest city': 'Seattle'}
Alternate approaches to defining dictionaries
Starting from an empty dictionary
Usng the
dictfunctionInput can be:
Empty - creates an empty dictioary
Tuple of tuples or list of tuples or list of lists
A dictionary
state2 = {}
state2['name'] = 'Oregon'
state2['capital'] = 'Salem'
state2['largest city'] = 'Portland'
state2
{'name': 'Oregon', 'capital': 'Salem', 'largest city': 'Portland'}
state3 = dict((['name', 'Idaho'], \
('capital', 'Boise'), \
('largest city', 'Boise')))
Operations/Methods#
len(d)The number of items (i.e., key-value pairs) in the dictionary
d[key]Returns the value associated with the given key
If key is not present, raises an exception
d[key] = valueAssigns the value to the given key
Adds the key-value pair if key is not present
del d[key]Delete the item
Raises an exception if key is not present
key in dReturns True if key is present in d, otherwise False
d.keys()Returns a view of the keys in d
d.values()Returns a view of the values in d
d.clear()Clears all the items
d.pop(key)Pops the item with the key if present, else raises an exception